🏗️ 设计构思
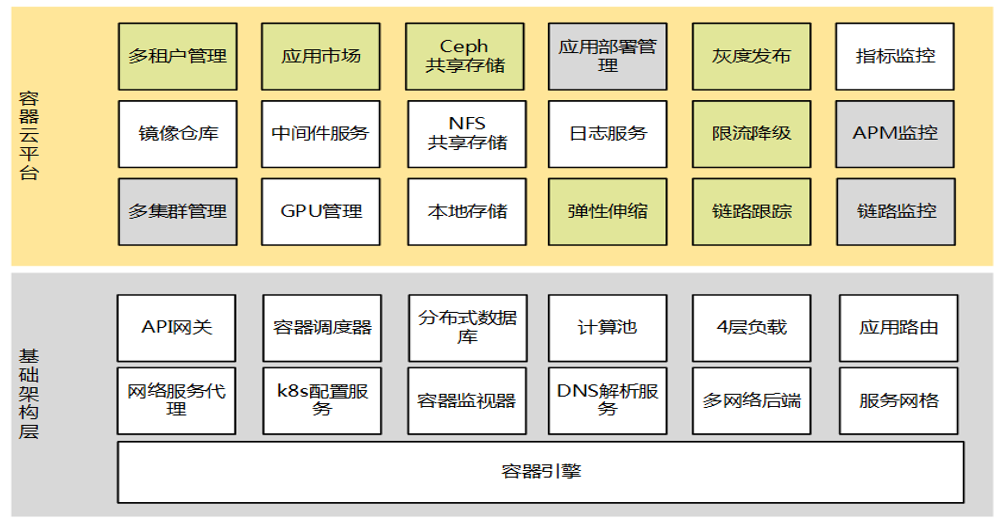
平台应有能力
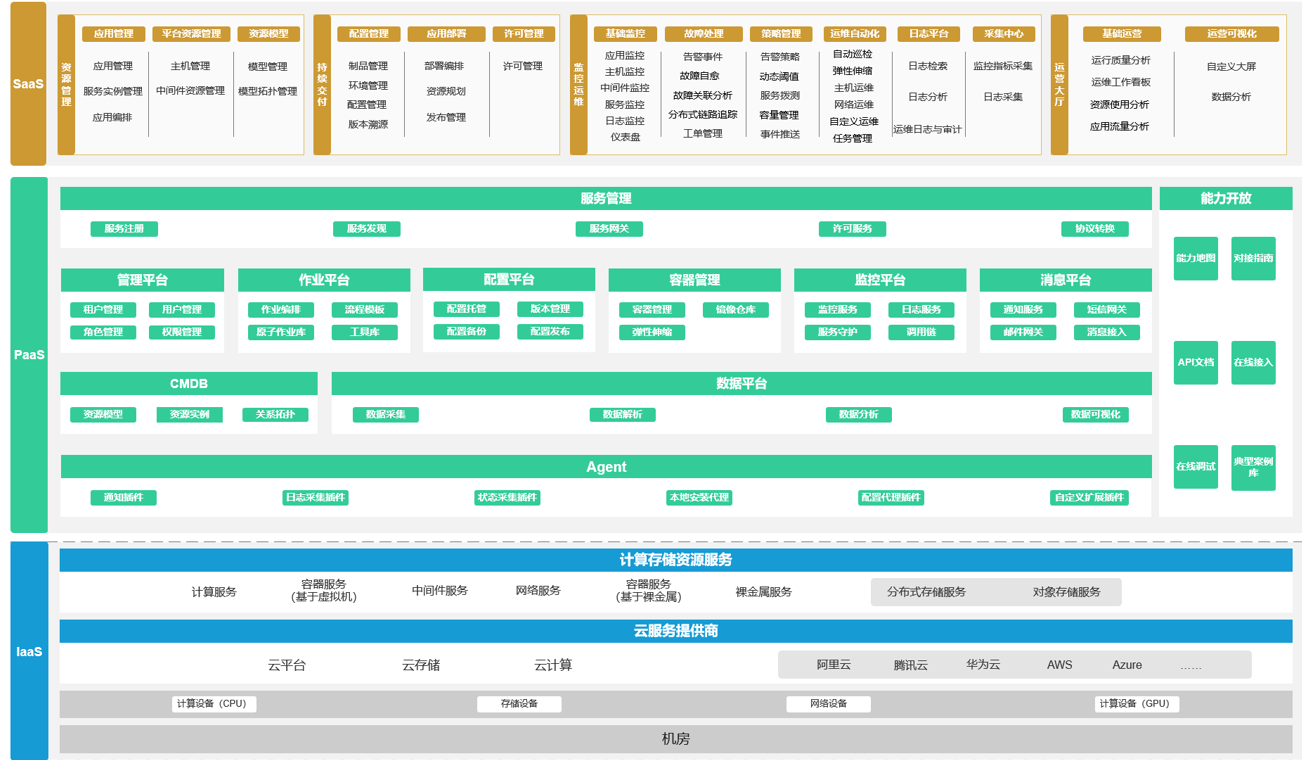
-
SaaS
-
最上层专注于业务的系统
-
-
aPaaS
-
自建基础应用服务平台,如网关、用户中心、认证中心、支付中心等共性业务组成的平台
-
-
iPaaS 自建基础环境:中间件、Runtime、监控系统、日志系统等组成的基础设施平台
-
IaaS 依赖第三方:阿里云、华为云、腾讯云等,包含服务器、存储、网络、操作系统
另外数据达到一定量,考虑自建数据平台 DaaS
🔭 云原生系统的设计理念 [1]
-
面向分布式设计(Distribution)
-
容器、微服务、API 驱动的开发
-
-
面向配置设计(Configuration)
-
一个镜像,多个环境配置
-
-
面向韧性设计(Resistancy)
-
故障容忍和自愈
-
-
面向弹性设计(Elasticity)
-
弹性扩展和对环境变化(负载)做出响应
-
-
面向交付设计(Delivery)
-
自动拉起,缩短交付时间
-
-
面向性能设计(Performance)
-
响应式,并发和资源高效利用
-
-
面向自动化设计(Automation)
-
自动化的 DevOps
-
-
面向诊断性设计(Diagnosability)
-
集群级别的日志、metric 和追踪
-
-
面向安全性设计(Security)
-
安全端点、API Gateway、端到端加密
-
问题&解决方案
| 问题 | 解决方案 |
|---|---|
Session |
分布式缓存 |
缓存 |
分布式缓存 Redis |
Queen |
消息中间件 |
日志 |
EFK方案,中心存储和查询 |
配置文件 |
配置中间件:apollo、nacos、configServer |
本地持久化数据 |
第三方分布式存储 |
IP会变 |
服务寻址 |
长连接中断 |
重连机制 |
日志采集 [2]
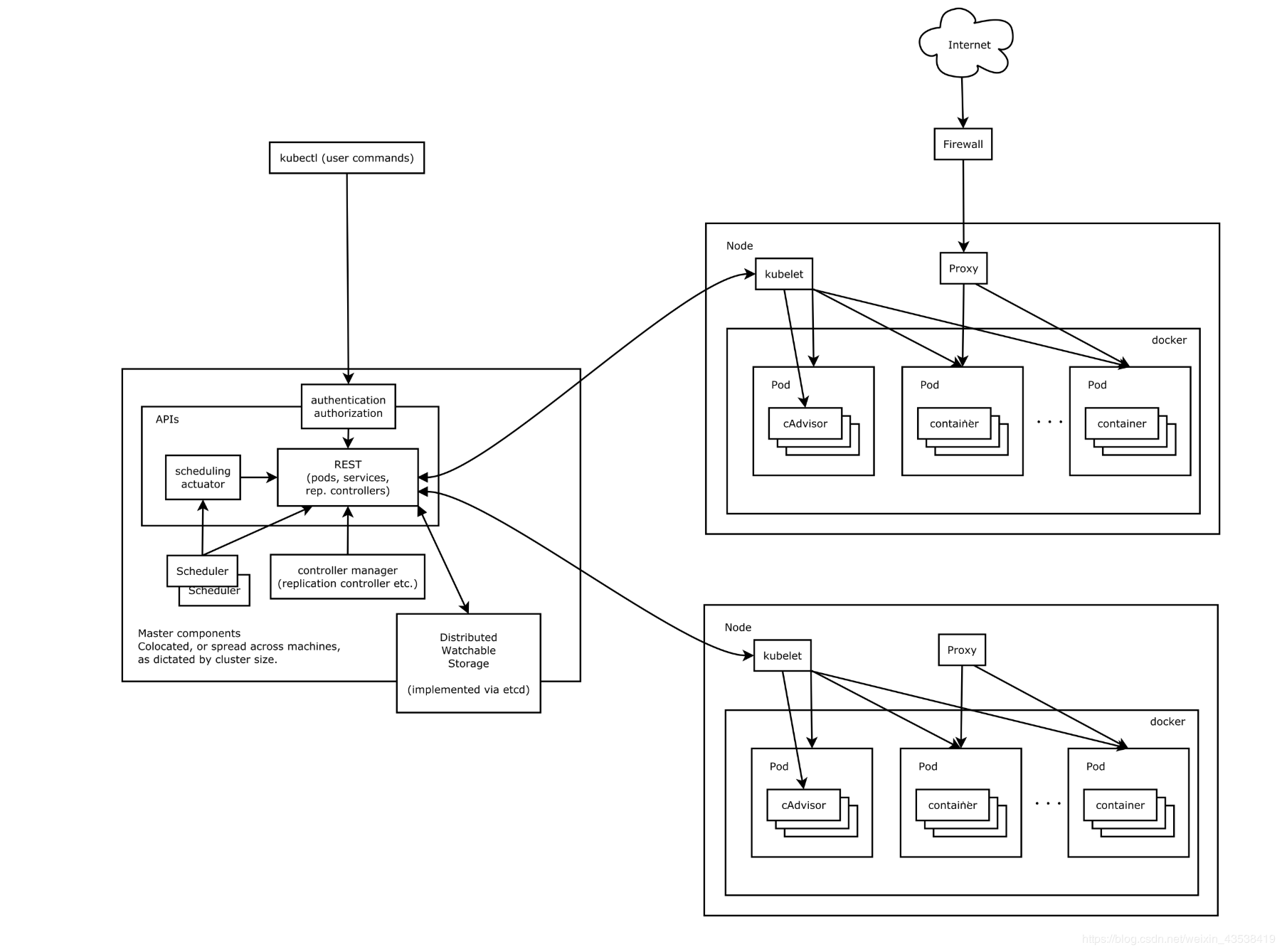
K8s
-
ControllerManage 负责维护集群的状态,比如故障检测,扩缩容,滚动更新等等。
-
Scheduler 负责资源的调度,按照预定的策略把pod调度到指定的node节点
-
ETCD 用做已执行存储,pod, service的集群等信息,k8s需要持久化的数据都存储在这个上边。
-
Kubele 负责维护当前节点上的容器的生命和 volumes,网络
-
每个 Node 上可以运行一个 kube-proxy,负责 service 提供内部的服务发现和负载均衡,为 service方法做个落地的功能。
-
kube-dns 负责整个集群的dns服务,这个组件不是必须的,一般通过名字访问比较方便。
-
dashboard 集群数据的GUI界面。